ai
Tensor Language Model Generates Optimized Tensor Schedules Without Search
A new generative compiler framework called Tensor Language Model uses a GPT-2 architecture to produce optimized tensor program schedules directly from learned patterns. The approach eliminates exhaustive search or reinforcement learning steps during compilation while maintaining competitive runtime performance on models such as ResNet-50, BERT, GPT-2, and LLAMA-7B.
May 18, 8:00 PM·1m read1 source
 nature.com
nature.comAudio version
Tap play to generate a narrated version.
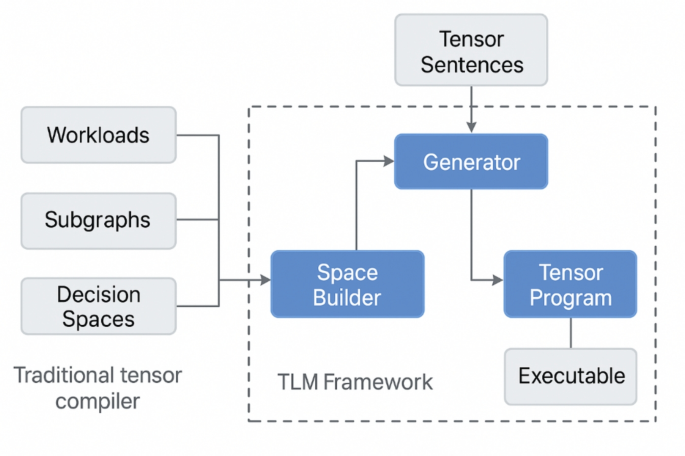
Com describes a Tensor Language Model (TLM) that frames tensor program scheduling as a language modeling task. The model is built on a GPT-2 architecture and pre-trained on millions of tensor programs represented as compact sequences that include operator graphs, hardware metadata, and reconfiguration choices.
TLM generates optimized schedules through direct inference rather than runtime search or reinforcement learning. 25 times faster than heuristic approaches such as Roller, while delivering similar execution performance.
Deep learning workloads have grown in complexity, requiring tensor programs that run efficiently across CPUs, GPUs, and specialized accelerators. Traditional vendor libraries provide hand-optimized kernels for common operations but are limited in generality and costly to maintain for new hardware or non-standard operators.
Automatic tensor compilers such as TVM, Halide, Ansor, and MetaSchedule address these limits by searching large spaces of possible code rewrites. Search-based systems can reach high performance but incur long compilation times, sometimes hours or days for large models, while heuristic systems reduce compilation time at the risk of missing optimal schedules.
TLM converts the scheduling problem into autoregressive sequence generation, allowing the model to produce context-sensitive decisions conditioned on operator structure and hardware properties. The paper reports that the resulting schedules achieve a balance between compilation speed and runtime efficiency across tested workloads.
Experiments covered ResNet-50, BERT, GPT-2, and LLAMA-7B. Results showed that TLM maintains execution performance comparable to existing methods while substantially reducing the time required to produce a working schedule. The framework is described as hardware-agnostic and reproducible, offering a generative alternative to current search or heuristic paradigms in deep learning compilation.


